머신 러닝으로 할 수 있는것
- 분류 (classification): 주어진 데이터 분류하기
- e.g., 특징을 기반으로 하여 어떤 과일인지 분류하기
- 회귀 (regression): 과거의 수치를 기반으로 미래의 수치 예측하기
- e.g., 과거의 주식 트렌드를 학습하여 미래의 주가가 어떻게 될지 예측, 날씨 예측 등
- 클러스터링 (clustering): 데이터를 비슷한 집합으로 분류하기 (classification 은 분류 항목을 미리 정하고 그에 따라 분류하는데 반해, clustering 은 미리 결정된 항목 없이 데이터를 비슷한 것으로 묶는 작업.)
- e.g., 소비자의 소비 데이터를 기반으로 한 데이터 분류 작업
- 추천 (recommendation): 관련된 데이터 제공하기
- e.g., 현재까지 구매한 내역을 바탕으로 한 물건 구매 추천
- 차원 축소 (dimensionality reduction): 데이터의 실질적인 특징과 관련 없는 특징 없애기
- e.g., 식품에 포함된 다양한 성분으로부터 규칙을 추출할때 불필요한 차원을 줄여서 처리
머신 러닝을 적용할 수 있는 분야
- 이미지 처리: 이미지 내의 물체 판정
- e.g., 얼굴인식
- 음성 처리: 음성을 텍스트로 변환하거나 특징 판정
- e.g., 특정 동물의 울음소리 판정, 성별 판정
- 텍스트 처리: 문장의 카테고리를 나누고 특정 표현을 추출 및 구문분석
- e.g., 스팸 메일 판정, 뉴스 / 블로그 기사의 카테고리 자동 분류, 구문 문석 및 자동 번역
머신 러닝의 종류
- 지도 학습 (supervised learning): 데이터와 함께 정답이 주어지고, 미지의 데이터를 예측
- 학습데이터와 분류에 대한 레이블 (답)을 함께 제공. e.g., 과일 분류시 특징 정보와 정답을 함께 제공.
- 비지도 학습 (unsupervised learning): 정답 데이터가 주어지지 않고, 미지의 데이터에서 규칙성을 발견
- 데이터를 외적인 기준 없이 자동 분류하여, 데이터의 본질적인 구조를 확인할 때 사용. e.g., 클러스터링 (쇼핑 데이터를 기반으로 특정 소비자들이 어떤 구매 트렌드를 갖고있는지 분석)
- 강화 학습 (reinforcement learning): 행동을 기반으로 정답인지 알려주며, 데이터에서 최적의 답을 찾아냄
- 게임 등에서 슈퍼 마리오 (에이전트) 가 특정 상황에서 (환경) 점프할때 가장 높은 점수를 받는 쪽으로 학습하도록 함. 여러 반복적인 행동을 통해 최적의 행동을 학습.
머신 러닝 기본 순서
목표 설정 => 데이터 수집 => 데이터 가공 => 데이터 학습 => 모델 평가 모델 평가 후 정답률이 잘 나오지 않을 경우 데이터 학습 재수행. 이후 실무에서 활용.
머신 러닝 알고리즘 선택 시 참고자료
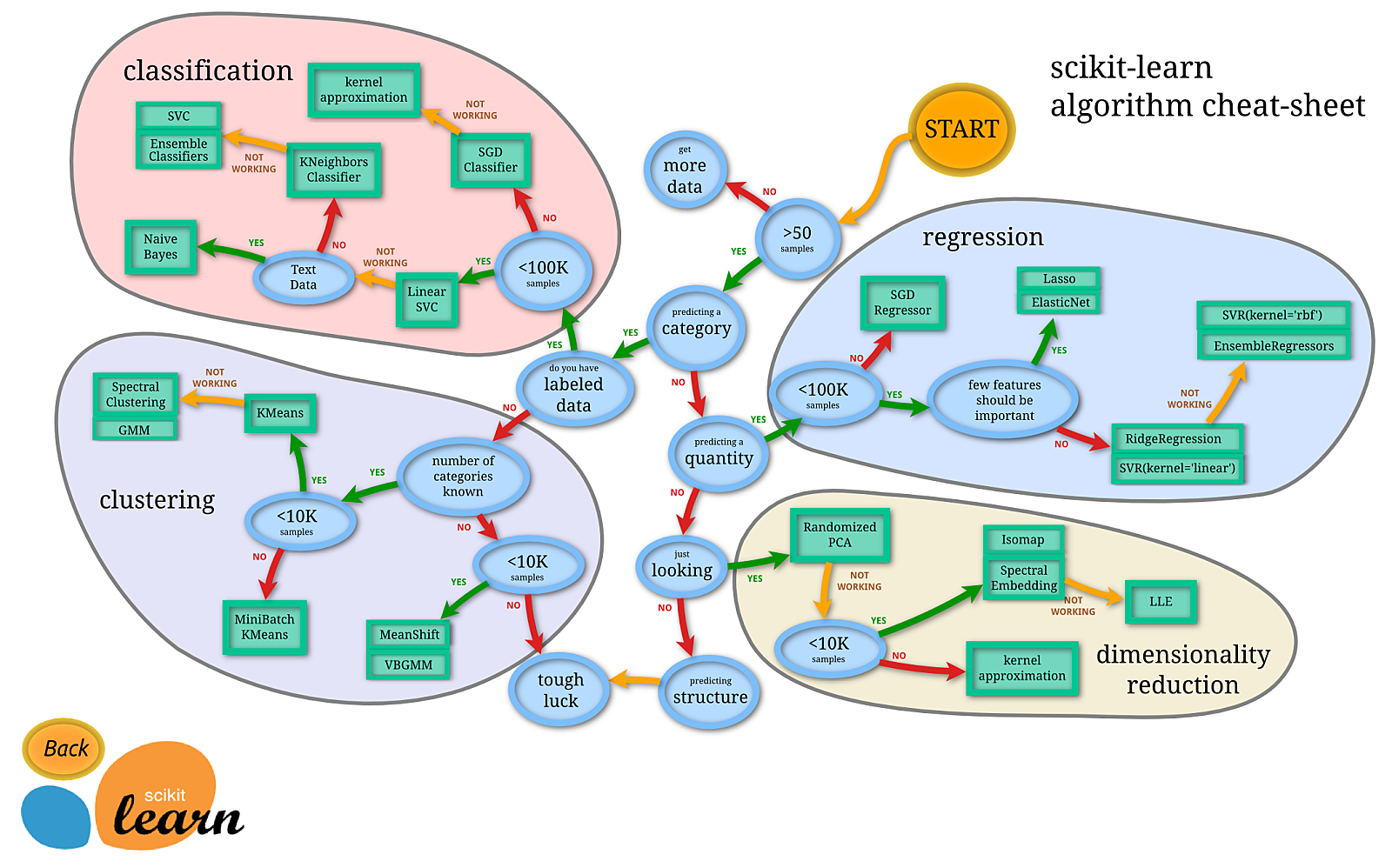
이미지 출처 : https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
0 Comments
