기계 학습 (머신 러닝, Machine Learning) 을 적용하기 위해서는 특정 입력 셋에 대한 출력값이 정의되어야 하고, 이에 맞는 적합한 알고리즘을 적용하여 예측을 수행하면 됩니다. 이러한 작업 외에도 이상치/특이치 및 무효값 제거 등 다양한 작업이 필요한데, 이 글에서는 이러한 작업을 생략하고 최대한 간단한 예제로 작업해 보려고 합니다. 이 글에서는 AND 연산자에 기계 학습을 적용합니다.
AND 연산자는 참 (True) 와 거짓 (False) 두가지 상태값을 가지는 두 값에 AND 논리 연산을 수행하는 연산자입니다. AND 연산자는 입력값의 종류가 4가지로 한정되어 있고 간단하여 기계 학습 적용이 필요하지 않지만, 간단하기에 기계 학습이 어떤식으로 진행되는지 전반적인 흐름을 파악하기 좋아 소개하게 되었습니다.
데이터
AND 연산자에 대한 데이터셋은 간단합니다. AND 연산자에 대한 진리표 (Truth Table)를 그대로 csv 데이터에 아래와 같이 입력하였습니다.

위 그림과 같이, 데이터는 총 3개의 칼럼을 갖고 있습니다. 칼럼 A 와 B는 AND 연산의 입력값에 해당하고, Result 는 A 와 B의 연산을 수행한 후의 출력값에 해당합니다. 위 csv 데이터를 파이썬의 pandas 라이브러리를 사용하여 불러온 후 작업을 수행합니다.
코드
아래와 같이 pandas 로 csv 파일을 읽어온 후, 불러온 데이터를 출력합니다.
import pandas as pd
train = pd.read_csv('train.csv')
train.head()
pandas 는 기본적으로 다양한 형태의 데이터셋을 불러올 수 있는 메서드를 내장하고 있습니다. 이중 하나가 csv 데이터를 불러오는 read_csv 메서드이고, 불러온 후의 train 변수값은 DataFrame (pandas.core.frame.DataFrame) 클래스의 형태로 저장됩니다. DataFrame 은 불러온 데이터를 출력하거나 다양한 형태로 가공하는 메서드들을 포함하고 있습니다. 위의 head 메서드는 데이터를 테이블 형태로 출력해주는데, 파라메터에 숫자값이 있는 경우 테이블의 첫 n줄만을 출력합니다.
- pandas.read_csv(filepath_or_buffer: str, ...): csv 파일을 읽어오는 메서드. 첫번째 파라메터는 csv 파일 경로. 이후 파라메터는 공식 문서 참조.
- DataFrame.head(n: Int = 5): n 번째 줄까지의 데이터를 출력하는 메서드. 기본값 5. (끝에서부터 표출시 tail 메서드 사용)
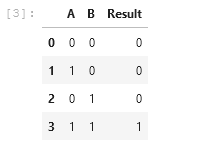
train.head() 호출 시 위와 같이 테이블이 출력됩니다. train 변수에 잘 저장된 것을 확인하였으니 이제 본격적인 머신 러닝 작업을 시작합니다.
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
위에서 import 한 scikit-learn 패키지는 대표적인 파이썬의 기계 학습 라이브러리입니다. 이 글에서 사용할 알고리즘은 선형 서포트 벡터 분류 (Linear Support Vector Classification, Linear SVC) 기법으로, 이진 데이터의 분류 작업을 수행하는데 비교적 좋은 성능을 보여준다고 알려진 기법입니다.
metrics.accuracy_score 은 정답률을 계산하는데 사용하는 클래스입니다.
clf = LinearSVC()
x = train.drop(['Result'], axis=1)
y = train['Result']
clf.fit(x, y)
알고리즘을 지정한 후, x와 y 변수를 정의합니다. 여기서 x 는 기계 학습 모델의 입력값으로, DataFrame.drop 메서드를 사용하여 테이블 내 출력값인 Result 칼럼을 제거합니다. y 변수는 학습시키고자 하는 모델의 예상 출력값으로, Result 칼럼만을 y 변수에 입력하였습니다. 이후, 정의된 학습 데이터 x, y 를 fit 메서드를 사용하여 학습시킵니다.
clf.coef_

위의 coef 는 상관계수 (Correlation Coefficient) 의 약자로, 두 변수간의 연관된 정도를 나타냅니다. 값이 1 또는 -1 에 가까울수록 양/음적 상관관계가 강하게 있다는 것을 의미하는데, AND 연산자에 대한 상관관계는 0.5 인것으로 나왔으므로, 이는 비교적 뚜렷한 양적 상관관계가 있다는 것을 의미합니다.
이제 학습된 모델에 대한 테스트를 수행할 차례입니다.
test = train.drop(['Result'], axis=1)
test
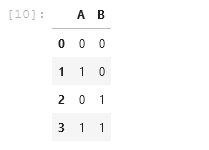
일반적으로 학습 데이터와 테스트에 사용되는 데이터는 중복으로 사용하지 않으며, 처음에 학습을 수행할 당시 특정 비율 (e.g., 8:2, 7:3) 로 나누어 모델의 정확도를 측정하는데 사용합니다. 이 예제에서는 편의상 학습된 데이터를 테스트에 그대로 사용하였습니다. 위 표와 같이 Result 칼럼을 제외한 입력값들만을 사용하여 test 변수에 입력을 하였습니다. 이후, 아래와 같이 테스트를 수행합니다.
result = clf.predict(test)
result
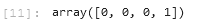
예측을 수행한 결과값을 확인해본 결과, 입력값과 동일하게 나오는 것을 확인할 수 있습니다. 데이터를 직접 코드로 정의할 경우 아래와 같이 입력할 수도 있습니다.
result = clf.predict([[0, 0], [1, 0], [0, 1], [1, 1]])
result
위 두 코드는 동일한 작업을 수행하는 코드입니다. 예측을 수행해 보았으니 마지막으로 정답률을 확인해볼 차례입니다.
# 아래 두 코드는 동일한 작업을 수행함.
accuracy_score(train['Result'], result)
accuracy_score([0, 0, 0, 1], result)
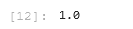
훈련한 데이터가 모두 예상한 출력값과 동일하므로 정답률은 1.0 으로 출력되었습니다. 정답률은 정답 출력값 개수 / 총 출력값 개수입니다. 이것으로 AND 연산자를 기반으로 한 간단한 선형 서포트 벡터 분류 기계학습 기법을 적용하는 예제를 마칩니다.
References
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.head.html https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html https://gomguard.tistory.com/173
3 Comments

다음글이 너무 기대가 되어 오늘밤 잠을 이룰 수 없을것 같사옵니다